[1] Ji Yang, Xinyang Yi, Derek Zhiyuan Cheng, Lichan Hong,
Yang Li, Simon Xiaoming Wang, Taibai Xu, and Ed H. Chi., "
Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations",
Companion Proc. of the Web Conference 2020 (WWW'20), Taipei, April 2020.
[Abstract] [Paper] [Citations]
Learning query and item representations is important for building large scale recommendation systems. In many real applications where there is a huge catalog of items to recommend, the problem of efficiently retrieving top k items given user’s query from deep corpus leads to a family of factorized modeling approaches where queries and items are jointly embedded into a low-dimensional space. In this paper, we first showcase how to apply a two-tower neural network framework, which is also known as dual encoder in the natural language community, to improve a large-scale, production app recommendation system. Furthermore, we offer a novel negative sampling approach called Mixed Negative Sampling (MNS). In particular, different from commonly used batch or unigram sampling methods, MNS uses a mixture of batch and uniformly sampled negatives to tackle the selection bias of implicit user feedback. We conduct extensive offline experiments using large-scale production dataset and show that MNS outperforms other baseline sampling methods. We also conduct online A/B testing and demonstrate that the two-tower retrieval model based on MNS significantly improves retrieval quality by encouraging more high-quality app installs.
[2] Xiaolan Wang, Xin Luna Dong,
Yang Li and Alexandra Meliou, "
MIDAS: Finding the Right Web Sources to Fill Knowledge Gaps",
Proc. of the 35th IEEE International Conference on Data Engineering (ICDE'19), Macau SAR, China, April 2019.
[Abstract] [Paper] [Citations]
Knowledge bases, massive collections of facts (RDF triples) on diverse topics, support vital modern applications. However, existing knowledge bases contain very little data compared to the wealth of information on the Web. This is because the industry standard in knowledge base creation and augmentation suffers from a serious bottleneck: they rely on domain experts to identify appropriate web sources to extract data from. Efforts to fully automate knowledge extraction have failed to improve this standard: these automated systems are able to retrieve much more data and from a broader range of sources, but they suffer from very low precision and recall. As a result, these large-scale extractions remain unexploited. In this paper, we present MIDAS, a system that harnesses the results of automated knowledge extraction pipelines to repair the bottleneck in industrial knowledge creation and augmentation processes. MIDAS automates the suggestion of good-quality web sources and describes what to extract with respect to augmenting an existing knowledge base. We make three major contributions. First, we introduce a novel concept, web source slices, to describe the contents of a web source. Second, we define a profit function to quantify the value of a web source slice with respect to augmenting an existing knowledge base. Third, we develop effective and highly-scalable algorithms to derive high-profit web source slices. We demonstrate that MIDAS produces high-profit results and outperforms the baselines significantly on both real-word and synthetic datasets.
[3] David Gold, Takeo Katsuki,
Yang Li, Xifeng Yan, Michael Regulski, David Ibberson, Thomas Holstein, Robert Steele, David Jacobs, and Ralph Greenspan, "
The Genome of the Jellyfish Aurelia and the Evolution of Animal Complexity",
Nature Ecology and Evolution, 2018.
[Abstract] [Paper] [Citations]
We present the genome of the moon jellyfish Aurelia, the first genome from a cnidarian with a medusa life stage. Our analyses suggest that gene gain and loss in Aurelia is comparable to what has been found in its morphologically simpler relatives—the anthozoan corals and sea anemones. RNA-Seq analysis does not support the hypothesis that taxonomically restricted (orphan) genes play an oversized role in the development of the medusa stage. Instead, genes broadly conserved across animals and eukaryotes play comparable roles throughout the life cycle. All life stages of Aurelia are significantly enriched in the expression of genes that are hypothesized to interact in protein networks found in bilaterian animals. Collectively, our results suggest that increased life cycle complexity in Aurelia does not correlate with an increased number of genes. This leads to two possible evolutionary scenarios: either medusozoans evolved their complex medusa life stage (with concomitant shifts into new ecological niches) primarily by re-working genetic pathways already present in the last common ancestor of cnidarians, or the earliest cnidarians had a medusa life stage, which was subsequently lost in the anthozoans. While we favor the earlier hypothesis, the latter is consistent with growing evidence that many of the earliest animals were more physically complex than previously hypothesized.
[4]
Yang Li, Bo Zhao, Ariel Fuxman and Fangbo Tao, "
Guess Me If You Can: Acronym Disambiguation for Enterprises",
Proc. of the 56th Annual Meeting of the Association for Computational Linguistics (ACL'18), Melbourne, Australia, July 2018.
[Abstract] [Paper] [Video] [Citations]
Acronyms are abbreviations formed from the initial components of words or phrases. In enterprises, people often use acronyms to make communications more efficient. However, acronyms could be difficult to understand for people who are not familiar with the subject matter (new employees, etc.), thereby affecting productivity. To alleviate such troubles, we study how to automatically resolve the true meanings of acronyms in a given context. Acronym disambiguation for enterprises is challenging for several reasons. First, acronyms may be highly ambiguous since an acronym used in the enterprise could have multiple internal and external meanings. Second, there are usually no comprehensive knowledge bases such as Wikipedia available in enterprises. Finally, the system should be generic to work for any enterprise. In this work we propose an end-to-end framework to tackle all these challenges. The framework takes the enterprise corpus as input and produces a high-quality acronym disambiguation system as output. Our disambiguation models are trained via distant supervised learning, without requiring any manually labeled training examples. Therefore, our proposed framework can be deployed to any enterprise to support high-quality acronym disambiguation. Experimental results on real world data justified the effectiveness of our system.
[5] Furong Li, Luna Dong, Anno Langen and
Yang Li, "
Knowledge Verification for Long-tail Verticals",
Proc. of the 43th International Conference on Very Large Databases (VLDB'17), Munich, Germany, August 2017.
[Abstract] [Paper] [Citations]
Collecting structured knowledge for real-world entities has become a critical task for many applications. A big gap between the knowledge in existing knowledge repositories and the knowledge in the real world is the knowledge on tail verticals (i.e., less popular domains). Such knowledge, though not necessarily globally popular, can be personal hobbies to many people and thus collectively impactful. This paper studies the problem of knowledge verification for tail verticals; that is, deciding the correctness of a given triple.
Through comprehensive experimental study we answer the following questions. 1) Can we find evidence for tail knowledge from an extensive set of sources, including knowledge bases, the web, and query logs? 2) Can we judge correctness of the triples based on the collected evidence? 3) How can we further improve knowledge verification on tail verticals? Our empirical study suggests a new knowledge-verification framework, which we call Facty, that applies various kinds of evidence collection techniques followed by knowledge fusion. Facty can verify 50% of the (correct) tail knowledge with a precision of 84%, and it significantly outperforms state-of-the-art methods. Detailed error analysis on the obtained results suggests future research directions.
[6]
Yang Li, Shulong Tan, Huan Sun, Jiawei Han, Dan Roth and Xifeng Yan, "
Entity Disambiguation with Linkless Knowledge Bases",
Proc. of the 25th International World Wide Web Conference (WWW'16), Montréal, Québec, Canada, April 2016.
[Abstract] [Paper] [Slides] [Citations]
Named Entity Disambiguation is the task of disambiguating named entity
mentions in natural language text and link them to their corresponding
entries in a reference knowledge base (e.g. Wikipedia). Such disambiguation
can help add semantics to plain text and distinguish homonymous entities.
Previous research has tackled this problem by making use of two types of
context-aware features derived from the reference knowledge base, namely,
the context similarity and the semantic relatedness. Both features heavily
rely on the cross-document hyperlinks within the knowledge base: the
semantic relatedness feature is directly measured via those hyperlinks,
while the context similarity feature implicitly makes use of those
hyperlinks to expand entity candidates' descriptions and then compares
them against the query context. Unfortunately, cross-document hyperlinks
are rarely available in many closed domain knowledge bases and it is very
expensive to manually add such links. Therefore few algorithms can work
well on linkless knowledge bases. In this work, we propose the challenging
Named Entity Disambiguation with Linkless Knowledge Bases (LNED) problem
and tackle it by leveraging the useful disambiguation evidences scattered
across the reference knowledge base. We propose a generative model to
automatically mine such evidences out of noisy information. The mined
evidences can mimic the role of the missing links and help boost the LNED
performance. Experimental results show that our proposed method substantially
improves the disambiguation accuracy over the baseline approaches.
[7]
Yang Li, Peter Clark, "
Answering Elementary Science Questions by Constructing Coherent Scenes Using Background Knowledge",
Proc. of the Conference on Empirical Methods in Natural Language Processing (EMNLP'15), Lisboa, Portugal, September 2015.
[Abstract] [Paper] [Slides] [Video] [Citations]
Much of what we understand from text is not explicitly stated. Rather,
the reader uses his/her knowledge to fill in gaps and create a
coherent, mental picture or "scene" depicting what text
appears to convey. The scene constitutes an understanding of
the text, and can be used to answer questions that go beyond the text.
Our goal is to answer elementary science questions, where this
requirement is pervasive; A question will often give a partial
description of a scene and ask the student about implicit information.
We show that by using a simple "knowledge graph" representation
of the question, we can leverage several large-scale linguistic
resources to provide missing background knowledge, somewhat alleviating
the knowledge bottleneck in previous approaches.
The coherence of the best resulting scene,
built from a question/answer-candidate pair, reflects the confidence
that the answer candidate is correct, and thus can
be used to answer multiple choice questions. Our experiments show that
this approach outperforms competitive algorithms
on several datasets tested. The significance of this work is thus to show
that a simple "knowledge graph" representation allows a version of
"interpretation as scene construction" to be made viable.
[8] Fangbo Tao, Bo Zhao, Ariel Fuxman,
Yang Li and Jiawei Han, "
Leveraging Pattern Semantics for Extracting Entities in Enterprises"",
Proc. of the 24th International World Wide Web Conference (WWW'15), Florence, Italy, May 2015.
[Abstract] [Paper] [Citations]
Entity Extraction is a process of identifying meaningful
entities from text documents. In enterprises, extracting
entities improves enterprise efficiency by facilitating
numerous applications, including search, recommendation,
etc. However, the problem is particularly challenging on
enterprise domains due to several reasons. First, the lack
of redundancy of enterprise entities makes previous web-based
systems like NELL and OpenIE not effective, since using only
high-precision/low-recall patterns like those systems would
miss the majority of sparse enterprise entities, while using
more low-precision patterns in sparse setting also introduces
noise drastically. Second, semantic drift is common in enterprises
("Blue" refers to "Windows Blue"), such that public signals from
the web cannot be directly applied on entities. Moreover, many
internal entities never appear on the web.
Sparse internal signals are the only source for discovering
them. To address these challenges, we propose an end-to-end
framework for extracting entities in enterprises, taking
the input of enterprise corpus and limited seeds to generate
a high-quality entity collection as output. We introduce the
novel concept of Semantic Pattern Graph to leverage public
signals to understand the underlying semantics of lexical
patterns, reinforce pattern evaluation using mined semantics
, and yield more accurate and complete entities. Experiments
on Microsoft enterprise data show the effectiveness of
our approach.
[9] Huan Sun, Mudhakar Srivatsa, Shulong Tan,
Yang Li, Lance Kaplan, Shu Tao and Xifeng Yan, "
Analyzing Expert Behaviors in Collaborative Networks",
Proc. of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'14), New York, NY, USA, August 2014.
[Abstract] [Paper] [Slides] [Poster] [Citations]
Collaborative networks are composed of experts who cooperate
with each other to complete specific tasks, such as
resolving problems reported by customers. A task is posted
and subsequently routed in the network from an expert to
another until being resolved. When an expert cannot solve
a task, his routing decision (i.e., where to transfer a task) is
critical since it can significantly affect the completion time
of a task. In this work, we attempt to deduce the cognitive
process of task routing, and model the decision making of
experts as a generative process where a routing decision is
made based on mixed routing patterns.
In particular, we observe an interesting phenomenon that
an expert tends to transfer a task to someone whose knowledge
is neither too similar to nor too different from his own.
Based on this observation, an expertise difference based routing
pattern is developed. We formalize multiple routing
patterns by taking into account both rational and random
analysis of tasks, and present a generative model to combine
them. For a held-out set of tasks, our model not only
explains their real routing sequences very well, but also accurately
predicts their completion time. Under three different
quality measures, our method significantly outperforms all
the alternatives with more than 75% accuracy gain. In
practice, with the help of our model, hypotheses on how to
improve a collaborative network can be tested quickly and
reliably, thereby significantly easing performance improvement
of collaborative networks.
[10]
Yang Li, Chi Wang, Fangqiu Han, Jiawei Han, Dan Roth and Xifeng Yan, "
Mining Evidences for Named Entity Disambiguation",
Proc. of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'13), Chicago, IL, USA, August 2013.
[Abstract] [Paper] [Poster] [Citations]
Named entity disambiguation is the task of disambiguating
named entity mentions in natural language text and link
them to their corresponding entries in a knowledge base
such as Wikipedia. Such disambiguation can help enhance
readability and add semantics to plain text. It is also a
central step in constructing high-quality information network
or knowledge graph from unstructured text. Previous
research has tackled this problem by making use of various
textual and structural features from a knowledge base.
Most of the proposed algorithms assume that a knowledge
base can provide enough explicit and useful information to
help disambiguate a mention to the right entity. However,
the existing knowledge bases are rarely complete (likely will
never be), thus leading to poor performance on short queries
with not well-known contexts. In such cases, we need to collect
additional evidences scattered in internal and external
corpus to augment the knowledge bases and enhance their
disambiguation power. In this work, we propose a generative
model and an incremental algorithm to automatically
mine useful evidences across documents. With a specific
modeling of "background topic" and "unknown entities", our
model is able to harvest useful evidences out of noisy information.
Experimental results show that our proposed
method outperforms the state-of-the-art approaches significantly:
boosting the disambiguation accuracy from 43%
(baseline) to 86% on short queries derived from tweets.
[11]
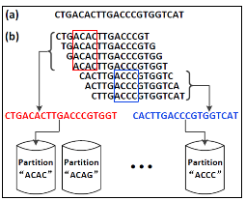
Yang Li, Pegah Kamousi, Fangqiu Han, Shengqi Yang, Xifeng Yan and Subhash Suri, "
Memory Efficient Minimum Substring Partitioning",
Proc. of the 39th International Conference on Very Large Databases (VLDB'13), Riva del Garda, Trento, Italy, August 2013.
[Abstract] [Paper] [Slides] [Press] [Citations]
Massively parallel DNA sequencing technologies are revolutionizing
genomics research. Billions of short reads generated
at low costs can be assembled for reconstructing the
whole genomes. Unfortunately, the large memory footprint
of the existing de novo assembly algorithms makes it challenging
to get the assembly done for higher eukaryotes like
mammals. In this work, we investigate the memory issue of
constructing de Bruijn graph, a core task in leading assembly
algorithms, which often consumes several hundreds of gigabytes
memory for large genomes. We propose a disk-based
partition method, called Minimum Substring Partitioning
(MSP), to complete the task using less than 10 gigabytes
memory, without runtime slowdown. MSP breaks the short
reads into multiple small disjoint partitions so that each
partition can be loaded into memory, processed individually
and later merged with others to form a de Bruijn graph.
By leveraging the overlaps among the k-mers (substring of
length k), MSP achieves astonishing compression ratio: The
total size of partitions is reduced from Θ(kn) to Θ(n), where
n is the size of the short read database, and k is the length
of a k-mer. Experimental results show that our method can
build de Bruijn graphs using a commodity computer for any
large-volume sequence dataset.
[12] Shulong Tan,
Yang Li, Huan Sun, Ziyu Guan, Xifeng Yan, Jiajun Bu, Chun Chen and Xiaofei He, "
Interpreting Public Sentiment Variations on Twitter",
Transactions on Knowledge and Data Engineering (TKDE'13), August 2013.
[Abstract] [Paper] [Citations]
Millions of users share their opinions on Twitter, making it a valuable platform for tracking and analyzing public
sentiment. Such tracking and analysis can provide critical information for decision making in various domains. Therefore it has
attracted attention in both academia and industry. Previous research mainly focused on modeling and tracking public sentiment.
In this work, we move one step further to interpret sentiment variations. We observed that emerging topics (named foreground
topics) within the sentiment variation periods are highly related to the genuine reasons behind the variations. Based on this
observation, we propose a Latent Dirichlet Allocation (LDA) based model, Foreground and Background LDA (FB-LDA), to distill
foreground topics and filter out longstanding background topics. These foreground topics can give potential interpretations of
the sentiment variations. To further enhance the readability of the mined reasons, we select the most representative tweets for
foreground topics and develop another generative model called Reason Candidate and Background LDA (RCB-LDA) to rank
them with respect to their "popularity" within the variation period. Experimental results show that our methods can effectively find
foreground topics and rank reason candidates. The proposed models can also be applied to other tasks such as finding topic
differences between two sets of documents.
[13]
Yang Li and Xifeng Yan, "
MSPKmerCounter: A Fast and Memory Efficient Approach for K-mer Counting",
arXiv.org preprint.
[Abstract] [Paper] [Software] [Citations]
A major challenge in next-generation genome sequencing (NGS) is to assemble massive overlapping short reads that are
randomly sampled from DNA fragments. To complete assembling,
one needs to finish a fundamental task in many leading assembly
algorithms: counting the number of occurrences of k-mers (length-k
substrings in sequences). The counting results are critical for
many components in assembly (e.g. variants detection and read
error correction). For large genomes, the k-mer counting task can
easily consume a huge amount of memory, making it impossible for
large-scale parallel assembly on commodity servers.
In this paper, we develop MSPKmerCounter, a disk-based
approach, to efficiently perform k-mer counting for large genomes
using a small amount of memory. Our approach is based on a novel
technique called Minimum Substring Partitioning (MSP). MSP breaks
short reads into multiple disjoint partitions such that each partition
can be loaded into memory and processed individually. By leveraging
the overlaps among the k-mers derived from the same short
read, MSP can achieve astonishing compression ratio so that the
I/O cost can be significantly reduced. For the task of k-mer counting,
MSPKmerCounter offers a very fast and memory-efficient solution.
Experiment results on large real-life short reads data sets demon-
strate that MSPKmerCounter can achieve better overall performance
than state-of-the-art k-mer counting approaches.